5. 복제
분산아키텍처의 주요주제
왜 복제하나?
- 고가용성 (HA) : High - 고, Availability - 가용성. 복제를 떠두어서 장애가 나더라도 복제본으로 서비스를 계속 이용할 수 있다는 의미
- 네트워크 중단 : 고가용성과 같은 맥락. 일부 복제본이 통신이 되지 않는 경우를 대비. 지리적으로 분리된 데이터 센터에 복제본을 유지하는 등
- 확장성 : 사용자가 너무 많아서 “통” 하나로 감당이 안됨. 복제본을 늘려서 대응
- 지연시간 : 사용자에게 응답을 빨리 주기 위해 한국/미국 사용자 위치에 따라 복제 데이터 배치
가정 (假定) ~ 본 “챕터”에서는 다음과 같이 가정한다.
- “장비 1대에 모든 데이터를 저장할 수 있다”
- 일단, “복제” 주제에 대해서는 데이터 크기, 스토리지 용량 제한 등은 배제하고 다룸. 1대에 저장할 수 없는 문제는 파티셔닝에서 다룬다.
복제는 어렵다 ?
- 네
- 뭐가 어렵나?
- 원본과 복사본을 “동일하게 유지”(Consistency) 하기 어렵다
- 복제의 모든 문제는 “변경” (mutable) 에서 비롯
- “변경”을 어떻게 다루어야 “일관성(Consistency)”과 “가용성(Availability)” 사이에서 잘 만족시킬 수 있을까
- 변경을 안하는 것도 전략. Immutable
복제 방식
- “리더 개수”에 따라 구분
- “리더”는 왜 정하나?
- 일관성은 “하나”(single)를 상대하면 쉬워짐
- “병렬” 문제가 “단일”(single) 문제로 바뀜
- “복제”에서 일관성을 다루기 위한 방법으로 “리더”를 선출함 => 합의알고리즘 (Paxos, Raft , …)
- “리더”가 write 요청을 처리하고 팔로워들에게 전파 => 클라이언트의 “write 요청에 대한 응답” 시점이 중요
- 리더가 몇 개? 에 따라 동작방식, 장단점, 발생가능한 문제 및 해결방법이 다름
복제 타이밍
- AP or CP ? CAP theorem
- “어디까지 기다리냐”에 따라 trade-off
- 모든 팔로워가 write가 완료될 때 까지 기다림 => Availability 포기. 높은 Consistency
- 리더 write 완료만 기다림 => Consistency 포기. 대신 빠른 응답 (Availability)
- 일부 팔로워의 write 완료를 기다림 => 절충.
-
여기서 P는 Partition-Tolerance (분단 내성) : 장애(네트웍 분단) 상황에서 A냐 C냐를 따지는 것임. 시스템이 정상 일때는 A도 C도 만족. (책에서 CAP를 까는 대목임 - 네트웍 분단을 속성으로 넣은점과 장애상황에서의 A,C 선택의 문제를 일반적인 상황에서도 그런것 처럼 오인하게 만드는 부분. 그럼에도 학술적으로 참고할 가치는 있음)
- “어디까지 기다리냐”에 따라 trade-off
-
동기식 복제 : 모든 팔로워 기다림
-
비동기 복제 : 안기다림
- 반동기 복제 : 일부만 기다림

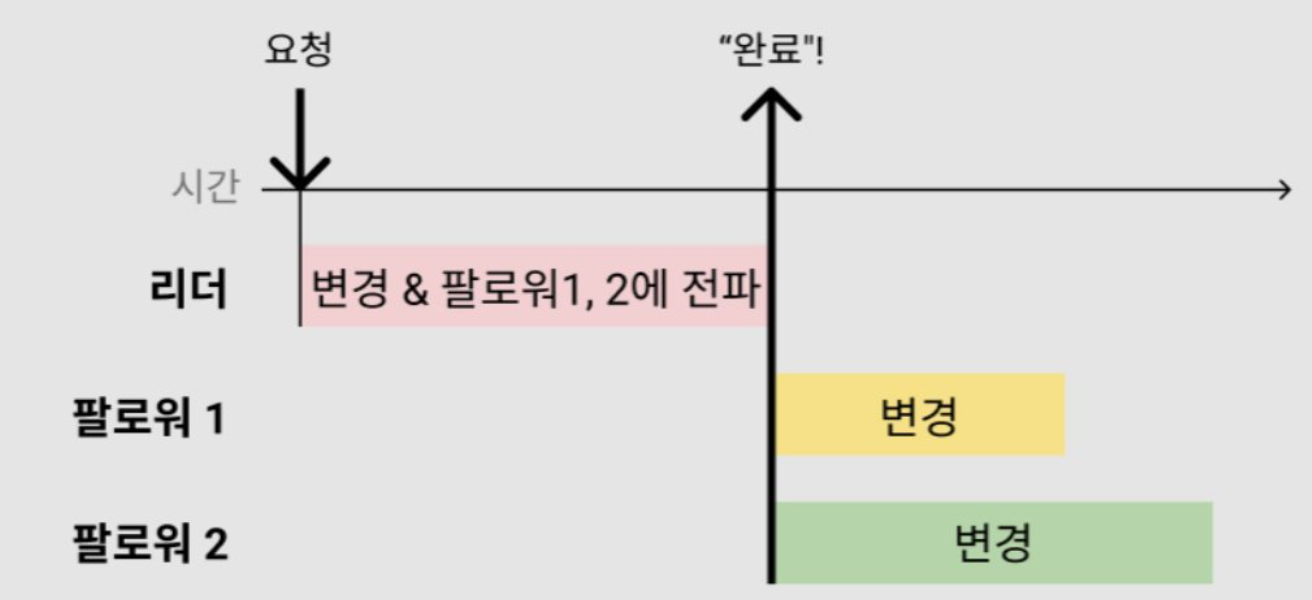

싱글리더 (주기만)
- Leader based replication == active-standby == priority-secondary == hot-standby (== master-slave 옛날표현)
- “싱글 스토리지” 처럼 다룰 수 있음. “쓰기 일관성”은 가져가면서 “복제”를 통한 “읽기 확장성” 확보
- 여기서 “리더”는 “싱글 write” 노드를 의미 (한 군데만 write)
- 누가 “리더”를 맡나? 관리자가 지정 or 투표 (합의알고리즘)
- Leader-Followers 패턴 ~ 리더 하나가 여러 팔로워를 거느리는 구조
- 리더는 read/write 모두 제공, 팔로워는 read only
- 리더는 write를 처리하고 모든 팔로워에게 “전달”할 책임이 있음
- 리더 장애, 팔로워 장애가 발생할 수 있고 대응방법이 다름
- write는 리더를 통해서만 처리돼야 하기 때문에 리더 장애가 나면 write 할 수 없음
- (장애 난) 기존 리더를 failover 하고 (혹은 관리자가 개입하여 복구하거나…)
- 새로운 리더를 선출하여야 write 할 수 있음
- 새로운 리더는 팔로워들 중에서 투표로 선출됨
- Old 리더와 New 리더 구분 필요 => 리더 교체에 따른 데이터 중복 및 누락 대응, 팔로워 싱크 등
- 리더 구분은 에포크(or TERM)로 함 (단조증가시계, Generation Clock) ~ 엘리자베스 1세, 2세, …
- Old 리더의 부활? (N/W순단 등) 되살아나는 경우가 생기더라도 “에포크”로 확인됨
- 현재 리더 에포크와 비교하여 작으면 Old 리더로 판단하여 처리를 취소하고 리더 지위가 폐위됨을 알려줌 (펜싱토큰 전략)
- write에 대한 응답 시점에 따라 Consistency 와 Availability를 조정할 수 있음
- Write 응답을 모든 팔로워 복제가 끝난 시점에 주면 응답은 느린 대신 모든 복제 노드가 일관성을 가짐 (동기식 복제)
- 반면, write 시 리더에만 쓰고 바로 응답을 주면 Client 입장에서는 덜 기다려도 되지만 팔로워 조회시 read 결과가 흔들릴 수 있음 (비동기식 복제) => 물론.. 언젠가는 싱크됨 (Eventually Consistency)
멀티리더 (주거니 받거니)
- Multi-leader == master-master == active-active
- Single 리더는 리더랑 통신이 안되면 write 할 수 없음 => write 받아줄 리더가 여러개라면?
- 리더가 여러개더라도 “복제는 같은 방식”임
- 쓰기를 처리하는 각 리더는 모든 다른 노드들에게 데이터를 전달해야 함 (포워드 책임)
- 멀티리더 구성에서 각 리더는 리더이면서 동시에 (다른 리더들에 대해서는) 팔로워 임
- “쓰기 충돌”이 발생할 수 있음
- 멀티리더 예시1) 데이터 센터별 리더
- 멀티리더 예시2) 오프라인 동기화 앱 ~ 캘린더, 메모,
- 멀티리더 예시3) 협업편집툴 ~ 위키, 깃
리더리스 (나 밖에 모름)
- 리더리스 ~ RDB 출현 이 후 한동안 잊혀진 방법
- 리더 컨셉은 싱글리더, 멀티리더 할 것 없이 “write는 하나의 리더가 처리한다”는 원칙에 기초
- 리더가 write 처리순서를 결정하고 팔로워들에게 그 순서에 따라 복제를 하게 됨 (포워드 책임)
- 리더리스는 위와 같은 “리더 컨셉을 포기”함
- 어떤 replica 든 write를 허용함
- 다른 replica에 대한 포워드 책임 없음 (나 밖에 모름. 리더와 팔로워는 서로를 아는 것과 대비됨)
- 아마존의 인하우스 Dynamo 시스템에서 시도
- (Dynamo 스타일) ~ “리악”, “카산드라”, “볼드모트” 등이 시도
- 리더리스는 클라이언트 혹은 코디네이터 노드를 통해서 replica 들로 복제를 수행하지만
- 코디네이터는 리더DB와는 달리 “쓰기 순서”를 강제할 수 없음
- 이러한 차이로 DB사용에 있어 심오한 결과를 초래함
- 리더리스는 장애가 나더라도 failover 가 없음. *failover? Active-standby switching
-
standby (follower) 개념 자체가 없음
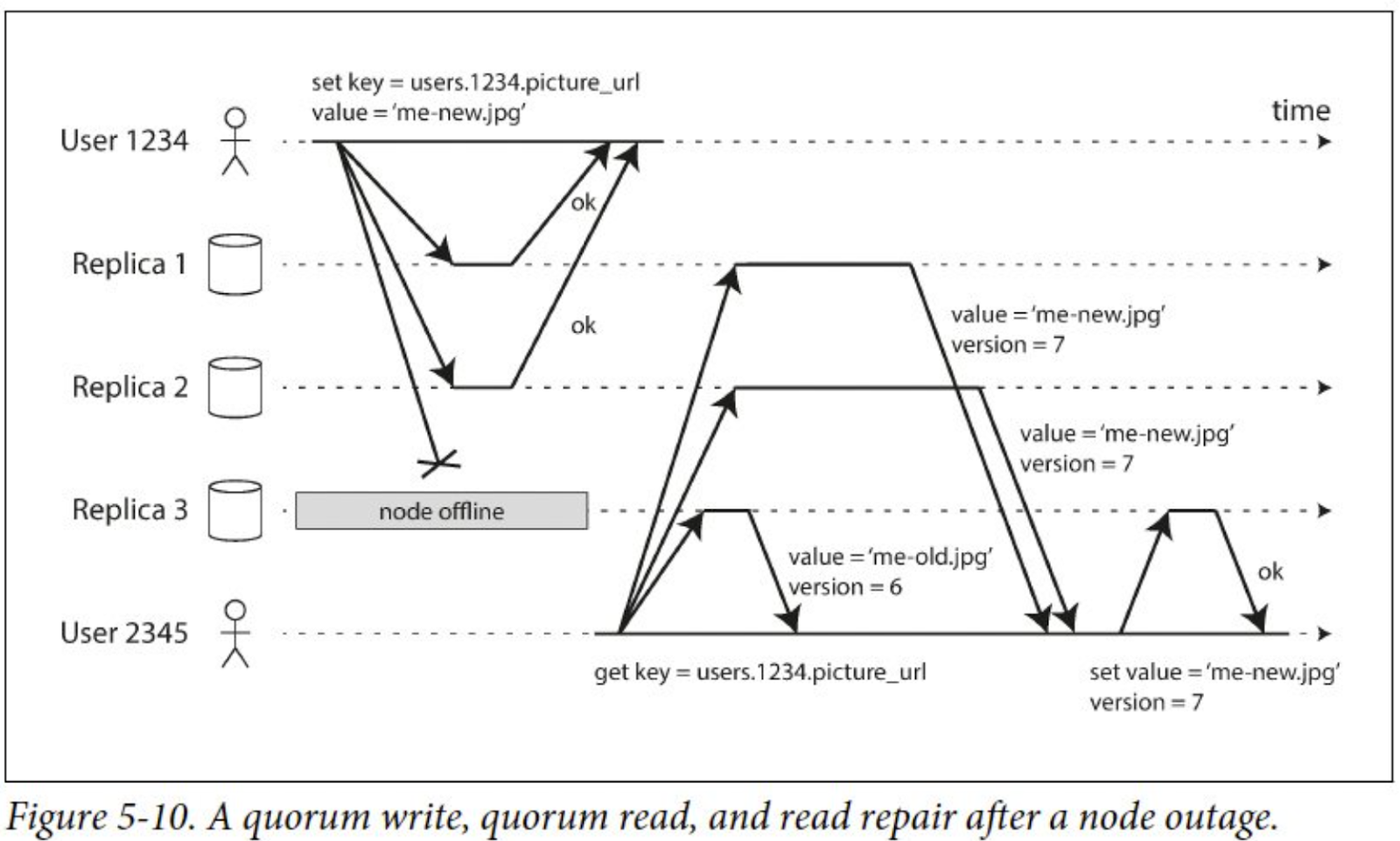
- 네트웍 순단 등 장애(그림에서 Replica3) 발생 => missing writes (쓰기 누락)
- 클라이언트(user2345)는 “모든 replica를 조회하여 결과비교” 후 사용
- 여기서 “결과 비교”에 사용되는 것이 버전 비교 (version 7 > 6)임
- missing writes 복구 방법 (Dynamo 스타일)
- Read repair : 이빨 빠진 데이터(version=7)를 client(user2345)가 write 해줌 (아우 귀찮..)
- 자주 read되는 데이터에 대해선 유용 => but, client read가 발생하지 않는 데이터는? (복구안됨)
- Anti-entropy process : 별도 백그라운드 프로세스를 두고 replica 간 데이터 차이를 지속적으로 비교해서 missing data를 메꾸는 방법 (아우 귀찮…)
- 싱글 리더 (복제로그) 처럼 순서 보장 안되고
- 데이터 copy 이전에 상당한 delay 발생 가능 (이빨 빠진 거를 비교해서 찾아야 함)
- 모든 Dynamo 스타일 시스템이 위의 복구방법을 모두 구현하지는 않음
- 볼드 모트는 anti-entropy 안함 => read repair만 하므로 read 없는 데이터는 복구 불가 (replica 불일치, consistency 보장안됨)
- 읽기/쓰기 정족수 (Quorum)
- 리더 구분없이 쓰기가 가능하므로 모든 노드에서 read/write 가능
- write의 경우 멀티리더와 마찬가지로 “쓰기 충돌”이 발생할 수 있음