9. 일관성과 합의
9장에서는 일관성 보장(Consistency guarantee)을 위한 합의(Consensus) 알고리즘에 대해 다룹니다.
- 도입부에서 부터 강력한 인상을 받습니다
“Is it better to be alive and wrong or right and dead ?” (DOA, Dead Or Alive)
분산시스템은 야생
- “Lots of things can go wrong” 많은 부분에서 언제든 잘못 될 수 있음
- 이러한 “Faults”를 해결하는 쉬운(?) 방법 => “전체 실패” (Entire Fail)도 한 방법!
- “잘”(확실하게) 죽는 것도 중요 ⇒ 문제를 잘 드러냅니다
- But, “안죽고 싶다!” “견디겠다!” ⇒ fault-tolerant 하게 해결하는 방법도 있습니다
- “죽을꺼냐” or “견딜꺼냐” ⇒ 선택의 문제입니다
- (8장에서 다룬) 분산시스템의 다양한 문제들
- packet lost, re-ordered, duplicated, delayed (패킷과 네트웍 문제)
- clocks are approximate at best (“근사치” 밖에 쓸 수 없는 시계 문제)
- node pause (GC), crash (노드 문제)
- 이렇게 문제 많고 무질서한 상황에서 견딘다는 것
- 올바른 “문제 정의”가 중요합니다
- 어떤 상황에서 어떻게 견딜 것인가, 구체화해야 합니다
- 문제가 정의되면 “해결 방법”을 찾을 수 있습니다
Abstraction
- 문제의 “범위”와 무엇을 “보장”하는지 정의
- 정의된 “문제”에 대한 합의된 “보장”을 제공
- 즉, 사용자는 해당 “문제”를 무시할 수 있게됨 (Abstraction이 “보장”)
- 그렇다고, 모든 문제를 해결해주는 것이 아닙니다
- 어떤 문제를 해결하고 어디까지 보장하는지
- 보장 “범위”를 잘 이해하고 써야 합니다
- Trade-off 를 따져봐야 합니다. (무엇을 얻고, 무엇을 잃는지)
- Abstraction 설계 ~ “General” 할 수록 가져다 쓰기 좋아요
- Abstraction 예시
- 트랜잭션(7장) : Atomicity 보장. 트랜잭션을 쓰는 사용자는 원자적 연산을 보장 받음
- 컨센서스(9장) : Consistency 보장. 컨센서스를 쓰는 사용자는 Consistency 문제(split-brain, data loss 등)를 고민하지 않아도 됨
트랜잭션이 보장하는 것
- No crashes
- Nobody concurrently accessing DB
- Storage durability
“보장”의 의미 ⇒ 먹어줌
- 실제로는 crashes, race conditions, disk failure 가 발생하더라도
- 트랜잭션 abstraction이 그러한 문제들에 대해 보장하므로
- 트랜잭션을 이용하는 애플리케이션은 구현에서 해당 문제를 다룰 필요가 없음 (구현 간결)
컨센서스
- 분산시스템에서 매우 중요한 Abstraction 중 하나
- 분산시스템에서 모든 노드의 “동의”(agree)를 얻는 방법
- “Reliably reaching consensus” 신뢰성있게 합의에 도달하도록 보장
- Network faults, process failures … 등 야생의 난관을 뚫고
- 예시 : “어느 싱글 리더의 죽음”
- New 리더 선출 필요 ~ “싱글 리더 복제” 아키텍처에서 “리더” 장애 발생
- 오직 하나의 리더만 선출하고 모든 노드가 여기에 동의해야 함
- “Split Brain” 문제 ~ “2개 노드”가 본인이 리더라고 하는 씨츄에이숀
- “Split Brain” 문제 ~ (리더라고 생각하는) 양 쪽 진영에서 write/forward가 발생 ⇒ data 불일치를 야기
- 컨센서스가 Split Brain 문제가 없도록 보장함 (나만 믿으라능)
Consistency Guarantees
- 분산환경에서 “일관성”을 어떻게 보장할까요
- “복제 지연” (Replication Lag)이 발생한다면?
- 리더 → 팔로워로 write 도착시점이 다름
- 어떤 팔로워를 보느냐에 따라 결과가 다름 (불일치, in-consistency)
- 이러한 불일치는 복제전략(싱글리더, 멀티리더, 리더리스)과 무관하게 발생
- 대부분의 복제DB는 최소한 “Eventual Consistency”를 보장함
Eventual Consistency
- 언젠가는 …
- 최종적 일관성
- 불일치 상태는 temporary 하고
- 중간에 어떤 Faults가 발생하더라도 결국엔 (Eventually) 해소되어
- 똑같아 지도록 (수렴하도록) “보장”함
- “언젠가는” 결과적으로 모든 팔로워들이 동일한 데이터로 수렴(Convergence) 할 것임
- But, (어딘가 찜찜해..)
- 네~ 물론.. 같아지긴 하겠지..만 이는 매우 “약한 보장”임
- 약한 보장 ~ 그래서 언제 똑같아 지는데?
-
모름. You know nothing …
- “자신이 쓴 내용 읽기” 예시
- 어떤 값을 쓰고 바로 읽으면, 방금 쓴 값을 볼 수 있는가
- (상황) Write → 리더, Read → 팔로워
- 리더에 write한 내용이 팔로워에 전파 되었는지 여부에 따라 다름
- “약한 보장”은 다루기 어려움
- “제한”(언젠진 모르겠지만 언젠간 같아질꺼라는 믿음) 을 계속 인지하고 있어야 함
- (뜻하지 않게) 너무 많은 “가정”을 하면 안됨
- 대체로 잘 동작하지만 버그는 미묘 ⇒ 테스트로 발견되기도 어려움 (그때그때 달라요~)
- Edge(예외) 케이스 ~ 발견 어려움. 시스템 결함 혹은 동시성이 높을 때만 드러남


선형성 ~ 선”형”아 사랑해
- 일관성 ~ 한 입 가지고 두 말 하지마
- 최신성 보장. “손흥민 골” 번복하지 않긔
- 약한 보장. 뭘 보장? 흔들리긴 하지만 언젠간 같아져
- 그래서, 그게 언젠데? 모름. ASAP?
- Recency guarantee 못함
- 선형성 - 강한보장 (선형아 💕 해…)
- 선형이는 말이지. 한 입 가지고 두 말 안해
- 우리 사겨? 응
- 근데.. 우리 사겨? 아니.. 엥? 너 선형이 아니지
- 선형적 읽기
- 쓰기 후 읽기보장. 쓰면 바로. (최신성 보장)
- 쓰기 중 읽기보장. 한 번 뱉은 응답은 보장한다.. 쓰기 중이라도 말이지 (엠바고 좀 ㅠ)
- CAS 중 읽기보장도 해주라. (어흑.. 그래) 원자적 CAS 는 비교(read)를 포함한 쓰기라 더 까다롭다
- 선형이는 어케 이리 강려크? “줄을 서시오-”
- 분산노드 간의 “사건”들을 다 줄을 세워
- 수사반장 ~ 기가 맥히게 수사잘함
- 여러 용의자들의 진술과 동선을 시간순으로 딱딱 짜맞춰가다 보면 .. 범인이 뙇. 사건해결 빡.
- 결국 모든 사건이 동일 시간”선”상에 매핑될 수 있다면 “순차”적으로 나열, 즉 “줄을 서시오” 할 수 있다
- 이것이 선형성임. 흔들리지 않는 편안함. 시몬스xx
- 결국 “한사람” 처럼 행동하길 원해 . 어디서 많이 본… (한남자가 있어 ~)
- 직렬성. 얘는 “트랜잭션”의 강한 격리
- 선형이는 “컨시스턴시”의 강한 보장
- 둘이 꼭 쌍둥이 같당 (구분하기 헷갈림) ⇒ But !! 추구하는바가 달라
- 선형이는 Strong Consistency(수사반장)
- 직렬이는 Strong Isolation(화장실락)
- 둘 다 다 “흔들리지 않는 편안함”을 추구
- 둘 다 “하나”인 것 처럼 행동하길 원함
- 직렬이는 연산들의 묶음인 트랜잭션 간의 “충돌”, “경쟁”을 막기 위함 (이어달리기, 트랙과 바톤)
- Recency guarantee ~ 선형이는 손흥민이 골을 넣으면 바로 그 소식이 변함없이 흔들리지 않고 알려주기 위함. (순서와 최신성을 보장)
선형성 시스템 구현의 어려움
- 단일 리더의 동기식 복제 => 고비용. 가용성 희생. 리더 선출 (선형적)
- 합의 알고리즘 (선형적)
- 멀티 리더 (비선형)
- 데이터센터 간 네트웍 장애
- 멀티리더: 각 데센리더 별 쓰기가능. But, inconsistency.
- 단일리더: 쓰기못함 or 리더 데센만 쓰기가능한 경우 inconsistency
- 데이터센터 간 네트웍 장애
- 리더리스 (비선형)
- 선형적 읽기 : 정족수 만족 (w+r > n) 하더라도 선형적이지 않음 (결과 흔들림)
- 네트웍 지연 등으로 다수가 old 값을 가질 수 있음. (진실이 다수결로 결정되는 문제)
- 선형적 쓰기 : 정족수로 부터 최신상태 읽기
- 선형적 CAS ~ 원자적으로 처리하려면? (정족수로) 불가. 읽기가 선형적이지 않기 때문.
- 선형적 읽기 : 정족수 만족 (w+r > n) 하더라도 선형적이지 않음 (결과 흔들림)
선형성의 비용
- 네트웍 단절 (net-split) => 선형성 vs 가용성 (데이터센터 간 네트웍 단절, 무엇을 선택?)
- 선형성 선택 : 쓰기 불가 (일관성 지킴) 예) 싱글리더
- 가용성 선택 : 일관성 깨짐 예) 멀티리더
- 판교화재 ~ 고객은 가용성 요구. 그렇더라도, 일관성 손해는 따져봐야 함.trade 가능한가
- CAP
- 선형성 요구 : “순서보장” + “최신성” 보장 (Strong Consistency)
- 네트웍 지연
- 심지어, 멀티코어 CPU도 “비선형”
- 코어별 캐시, 버퍼 레이어 및 비동기 갱신 (비선형) => Cache Coherence 보장 필요
- NUMA (Non-Uniform Memory Access)
- 왜 이렇게 만들었니 ? “성능” (선형성을 희생함)
- 그럼, 문제가 생기면 ? “정상 동작 안함” (성능을 위해 정상 동작을 포기함)
- 그래서 … ? 선형성은 느리고 성능이 안좋다 (증명도 됐다.. By 아티야/웰치)
- 효율적인 대안 ?
- 특히 “low latency” 시스템 (예. 검색)에서 trade-off 잘 따져야함
- 정확성을 희생하지 않고 선형성을 회피하는 방법은?
- 심지어, 멀티코어 CPU도 “비선형”
인과성 (Causal dependency)
- 선형성은 비싸고 힘들고 절충안으로써 인과성은 어때
- 이벤트 역전 (“추월”) 방지 :
- add -> update (O)
- update -> add (X) “추월”
- 동시성 => 인과성 없음. “알리바이” 사건과 무관함을 증명하라
- 일관된 스냅숏 => Consistent with Causality. 인과성에 일관적이란?
- 스냅숏에 답변이 있다면 질문도 포함돼 있음
- 최신성은 보장못함 ~ “선형적”이진 않다
- 쓰기 스큐와 팬텀 (p.246) ~ 인과적 의존성
- skew ~ timing anomaly
- 의사온콜 ~ 최소1명대기. 밥/앨리스 중에 먼저 휴가를 쓴다면 남은 사람은 온콜임
- 호출 대기 중인 의사목록 관찰에 “의존함”
- SSI 의 optimistic lock (CAS) 으로 쓰기 스큐 검출
- 채널간 타이밍 의존성
- 축구 중계와 앨리스의 탄성
- 인과적 일관성 (Causally Consistency)
- 인과성에 의해 부과된 순서를 지킴
- 인과성은 “부분 순서”를 보장 (선형성은 “전체순서”를 보장)
- 깃 브랜치
- 밥 공장에 폭탄설치 - a
- 앨리스 공장이동 - b
- 앨리스 공장도착 -> (merged) 빵!
- 깃 브랜치
Ordering Guarantees
- “순서 보장”
- 순서화 : 이 책의 주제, 근본적 아이디어
- 선형성 => 연산의 순서 보장
- 5장 복제 => 쓰기의 순서 보장
- 7장 트랜잭션의 직렬성 => (격리를 통해 트랜잭션 간에 연산이 섞이지 않게) 연산의 순서 보장
- 8장 타임스탬프와 시계 => 연산의 선후를 결정하기 위한 방법. 질서를 부여하려는 시도
왜 이런 고민을 하는가 ?
- 단일리더의 부하 ~ 모든 연산을 단일리더가 처리하는 부담
- 연산(부하)을 나누려면? ~ 연산들의 “순서”를 결정할 수 있어야 함
- 역할 분담과 일의 순서 ~ 동시에 할 수 있는 일과 순서가 필요한 일의 구분
How to Order (줄세우기)
일련번호 만들기 ~ “비인과적” vs “인과적”
“비인과적” 일련번호
- 단일 리더 O ~ 리더가 “순서”를 정하고 팔로워들은 사용함. 순서 정하기 쉽다.
- 단일 리더 X ~ 순서를 어떻게 정하나?
- “동시적”(서로 모름) 노드들이 각자의 연산에 일련번호를 사용하려면?
- 서로를 모르기때문에 불일치 (inconsistency) 야기
- 방법1) 홀 or 짝 ~ 홀수로 증가하는 노드와 짝수로 증가하는 노드
- 방법2) wall clock (일 시계)~ 노드 간 시계 불일치 이슈
- 방법3) 일련번호 블록 ~ 1)과 비슷
- “동시적”(서로 모름) 노드들이 각자의 연산에 일련번호를 사용하려면?
“인과적” 일련번호
- Causally Consistent (인과적 일관성) 보장
- “인과적”이란 ? 예시
- 질문 => 답변
- Add => Update
- 골인 => 골 취소
- “인과적”이란 ? 예시
- 인과적으로 “전체순서”를 보장할 수는 없을까? 있음
- 램포트 타임스탬프 => (카운터, 노드ID)
- 요청 마다 카운터 max 값을 전달
- 노드 ID(순서)를 부여함
- 수신처에서 Max(요청 max, 노드 max) 사용
- 요청max와 노드max가 동일한 경우 : 노드ID를 비교
- 사건의 “선후 판단” 가능
- 한계점 : “사후결정”만 가능
- “당장결정” 안됨
- 연산을 모아야 (max비교) “순서”를 알 수 있음
- 너 몇 살이야? (어서 반말이야~)
- 순서 확정할 방법 필요
- 사례) 신규 “사용자ID” 등록 => 확인할 수 없음
전체 순서 브로드캐스트 (Total Order Broadcast)
- “순서 확정”
- 쇼핑몰 특가 선착순 100명 or 청약당첨 100명
- 일단 번호표 발급 (순서확정)
- 번호순으로 처리
- 중간에 실패 발생하면 재시도하거나 다음 순번을 처리
- 그래서, 뭐라고? 글로벌 번호표 발급기
- 전제조건 : “무손실” (누락X), “순서고정” 전달
- 예시
- 복제
- 직렬성 트랜잭션
- 로그 적재와 순서대로 읽기
- 펜싱토큰 ~ 단조 카운터(토큰)의 크기 비교
- 전체순서 브로드캐스트를 이용한 “선형성 저장소” 구현 (싱글리더 복제와 같음)
- Append Only Log, MQ (ex. kafka)
- Append Only Log, MQ (ex. kafka)
- “선형성 저장소”를 이용한 전체순서 브로드캐스트 구현
- 선형성 레지스터를 이용한 카운터 ~ 틈이 없는 순열 형성
- 원자적 단조증가 => 연속적인 순서 보장
- 예) mysql auto_increment 번호표 발급
- 선형성 레지스터를 이용한 카운터 ~ 틈이 없는 순열 형성
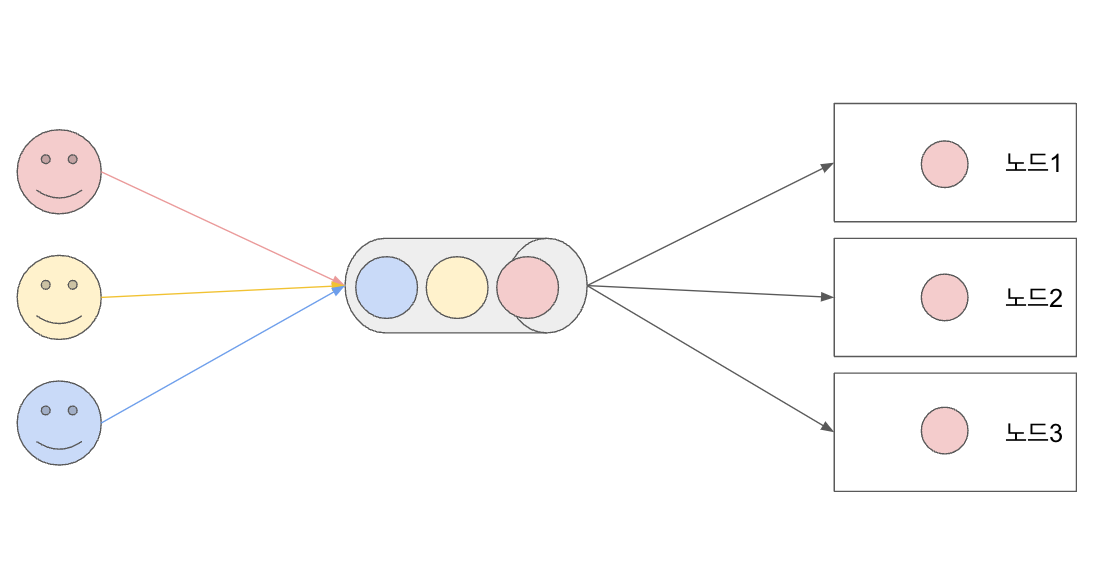
분산트랜잭션과 합의
- 합의 : 여러 노드들의 “동의”를 얻는 것
- 합의를 다루기 위한 선행지식 : “복제”, “트랜잭션”, “시스템 모델”, “선형성”, “전체순서브로드캐스트”
- “동의”가 필요한 상황 예시
- 리더선출 : split-brain 방지 (리더는 하나) => 합의 필요
- 원자적 커밋 : all or nothing => 합의 필요
- 합의 불가능성
- 죽을수 있으면 합의 불가 ⇒ 어떤 시계나 타임아웃 사용을 배제하는 가정
- But, “죽음”을 판별할 수 있거나 타임아웃이 있다면? 합의 가능
원자적 커밋과 2단계 커밋
- 원자적 커밋 vs 합의
- 원자적 커밋 : 만장일치
- 합의 : 제안과 결정
- 트랜잭션 “원자성”
- All or nothing
- 커밋 : 지속성 보장
- 어보트 : 완전한 롤백
- 원자적 커밋
- 단일노드
- 순서대로 (연산을) 디스크에 쓰고
- 최종 “커밋 레코드” 쓰기 성공 여부가 결정 : 커밋 or 어보트
- 분산노드는 어떻게?
- 노드별로 커밋 성공여부가 다를 수 있자낭 ~
- 커밋 실패한 노드가 있는 경우에 성공한 노드는 어떻게 되돌리냥 (어보트) ~
- 커밋 노드에 대한 어보트 시 어보트 소급은 어떻게 처리할 것이며 ~ (@,@a;; hell~)
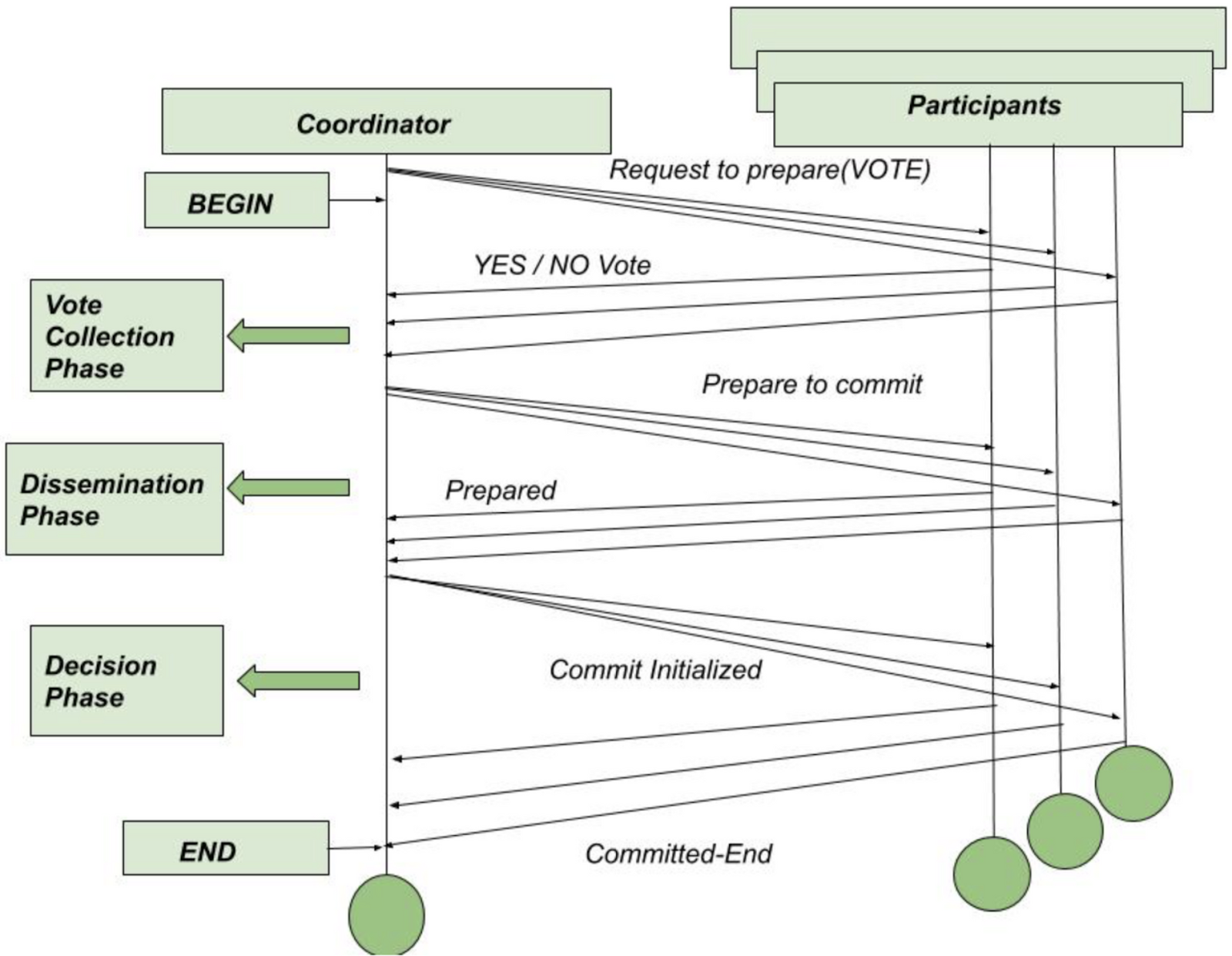
- 2PC, 나만 믿으랑께
- 분산 노드의 원자적 커밋 달성
- 커밋/어보트를 두단계로 달성
- “코디네이터”의 등장: 합의를 주관
- 등장인물 : 코디네이터, 참여자(participant)
- 1단계 (준비) : 모든 노드에 커밋 가부 확인
- 2단계 (커밋/어보트)
- 커밋 : 1단계에서 모두 “예”라고 응답한 경우
- 어보트 : 1단계에서 하나라도 “아니오” 라고 응답한 경우
- 코디네이터 장애
- “Blocking” 원자적 커밋 => 코디네이터 장애 => 트랜잭션을 완료할 수 없음
- (트랜잭션 완료하려면) “코디네이터 복구” 밖에 방법이 없음
- 코디네이터가 복구되어 트랜잭션을 완료하려면 ?
- “커밋포인트” (커밋 or 어보트 결정) 가 디스크에 쓰여야 함
- 분산 노드 간의 원자적 커밋 => “단일 노드”의 원자적 커밋
- 3PC 참고: https://www.geeksforgeeks.org/three-phase-commit-protocol/
- “Non-Blocking” 원자적 커밋
- 비현실적. 코디네이터 장애를 감수하고서라도 2PC가 계속 쓰임.
- Ready => Pre-commit => Commit (3 Phase)
-
코디네이터가 죽어도 (new) 코디네이터가 이어서 트랜잭션을 완료할 수 있음 (이론상)
- 전제조건 : No network partition, k (스레숄드) 개수 이상의 노드 실패 없음을 가정
- 코디네이터는 “디스크”에 커밋 결정을 기록하는 대신에, k 개수 이상의 participants 에 커밋결정을 알림 (Pre-commit)
- 코디네이터 장애 발생 시
- New 코디네이터로 participants 가 바운드되고
- New 코디네이터는 participants에 커밋결정을 확인함
- 커밋결정을 알고있는 participants (k개) 가 하나라도 있으면 해당 커밋결정을 따라서
- 마지막 Commit 단계를 restart 함
- 커밋결정을 알고 있는 participants가 없다면 트랜잭션을 abort 함
현실의 분산 트랜잭션
- 2PC는 너무 과하고, 3PC는 비현실적이고 …
- 분산 트랜잭션 ~ “안정성” 이냐 “성능” 이냐
- 분산 트랜잭션 꼭 해야 겠니 ?
- 분산 트랜잭션 ~ 같은 제품 vs 다른 제품/기술
- 정확히 한 번
- 이기종 환경에서 “exactly-once”를 보장?
- MQ로 부터 message를 pop해서 DB에 insert 하는 과정을 원자적으로 처리할 수 있나?
- 중복 저장이 발생하지 않도록
- 트랜잭션에 이메일 발송이 포함돼 있다면 롤백 시 되돌릴 수 있나 ?
- 일반적인 이메일 시스템으로는 불가함
- 이기종, 서로 다른 제품/기술 간에 무언가 약속이 필요하다
- XA 트랜잭션
- 이기종 트랜잭션 => “표준” (약속) 필요
- 표준 API와 라이브러리
- 이기종 분산 환경에서의 트랜잭션 문제를 (합의된) XA API를 이용하여
- XA 코디네이터를 구현한 애플리케이션의 “단일 원자적 커밋” 문제로 환원
- But, 여전히… 코디네이터 장애 문제는 남아 있음
- 코디네이터 장애와 “의심스러운 상태” (participants)
- 의심스러운 상태와 “Lock” 유지
- 코디네이터에 문제가 생기면 …
- (트랜잭션 중 읽기가 발생한) Row Lock ~ 해제 할 수 없음
- 커밋 or 어보트로 해소되기 전까지 ..
- 결국, 다시 코디네이터 복구 문제로 …
- 코디네이터 장애 복구
- “수동 조치” ~ 관리자가 판단 (책임)
- 결국, 사람이 개입할 수 밖에 없는가
- 분산 트랜잭션의 제약 장애를 증폭시키는 경향 ~ “내결함성을 지닌 시스템”을 구축하려는 목적에 어긋남
- 코디네이터 ~ SPoF
- app 이 코디네이터를 품는 순간 Stateful 해짐
- DB 애플리케이션 => State를 DB에 의존하는 대신 Stateless 해짐
- => But, 코디네이터 쓰는 순간 Stateful
- 코디네이터의 State 란 ? 트랜잭션 상태, participants 상태 등
- XA 한계 ~ 교착상태 탐지 어려움, SSI (Serializable Snapshot Isolation) 지원 어려움
- DB내부 분산 트랜잭션의 한계 ~ “모든 참여자의 응답” (동기식)
- => participant 하나라도 고장나면 실패
내결함성을 지닌 합의
– 합의? 여러 노드가 어떤 것에 동의 (agree)
– 합의 문제의 형식 : 제안과 결정
– 예) 좌석 예약. 동일 좌석에 대한 (여러) 고객ID제안과 하나의 고객ID를 결정
– 합의 알고리즘 요건
ㄴ 균일한 동의 (Uniform agreement)
ㄴ 무결성 (Integriry)
ㄴ 유효성 (Valididy)
ㄴ 종료 (Termination)
– “합의”에서 내결함성을 지니는게 어려움
– 2PC에서 보았듯 노드 장애 상황에서 “결정”을 내릴 수 있는가
– “종료” 보장 ~ 쿼럼 이상 노드 필요
– “안전성” (동의,무결성,유효성) 보장 ~ (장애로) 중단 되더라도 합의시스템을 오염시키지 않음
– 합의 알고리즘의 주요가정 ~ “비잔틴 결함” 없음 (1⁄3미만 배신자에는 견고)
합의 알고리즘과 전체 순서 브로드캐스트
– 내결함성 합의알고리즘 => 뷰스탬프 복제 (Viewstamped Replication, VSR)
– 구현 예) Paxos, Raft, Zab
– “전체 순서 브로드캐스트” 사용
– 모든 노드에게 메시지를 “정확히 한 번” + “같은 순서“로 전달 => 합의 과정
– 전송할 메시지를 “제안”하고, 전체순서(total order) 상에서 전달될 메시지를 “결정”함
– 전체순서브로드캐스트 구현 == 합의 구현
ㄴ 동의 : “같은 순서”로 전달 하도록 결정
ㄴ 무결성 : “중복”되지 않음
ㄴ 유효성 : 오염, 조작되지 않음
ㄴ 종료 : 메시지가 손실되지 않음
– 뷰스탬프 복제 : “전체 순서 브로드캐스트” 구현
– 전체 순서 브로드캐스트가 합의 요건을 충족하고 구현 상 합의를 여러번 하는 것보다 효율적임
– “전체 순서 브로드캐스트”를 “합의”와 동치로 끌어옴
단일 리더 복제와 합의
– 모든 쓰기를 리더가 처리하고
– 리더가 “같은 순서”로 팔로워에게 “전달” => “전체 순서 브로드캐스트” (== 합의)
– 그런데 왜 합의를 걱정했나? (5장)
– “리더 선택” 방법에 따라 다름
– 리더 선택 “수동” (사람개입) => 리더 장애 시 “쓰기” 중단 => 합의의 “종료” 속성 만족 못함
– 리더 선택 “자동” => 리더 장애 시 새로운 “리더 선출” => 내결함성 지닌 전체 순서 브로드 캐스트
– 리더 선출 => 합의가 필요 (리더 선출을 위해 리더가 필요한 난제)
리더없음 -> 리더선출(합의필요) -> 합의 == “전체순서”브로드캐스트 -> “전체순서”는 리더 복제 -> 리더필요 -> 리더없음
epoch 와 quorum
– 지금까지 살펴 본 합의 ~ 어떤 형태로든 “리더” 사용
– 예) 코디네이터 (동문회장)
– epoch 내에서 리더 유일 보장
– epoch == ballot (Paxos) == view (뷰스탬프복제) == TERM (Raft)
– epoch ~ 단조증가하는 total order
– epoch 증가 ~ **리더 선출 때마다
– 리더 충돌 시 ~ “epoch 높은 놈이 이긴다” (바닷거북이가 이긴다)
– 팔로워 ~ “얘가 리더 맞나? 더 높은 epoch 없나?” (의심하라1)
– 리더 ~ “내가 리더 맞나? 쫓겨나지 않았나?” (의심하라2)
– (까라면 까는 시대는 지났다. 일방적인 top–down “NO”)
– 투표로 결정하자 (quorum)
– 투표로 결정 ~ “리더의 제안”
– 리더는 모든 결정에 quorum 이상의 찬성이 필요하다
– (일방적으로 마스터가 write하고 슬레이브에게 배급하던 “노예”시대가 아님)
– 노드는 epoch 를 비교하여 더 높은 리더를 모를 경우에만 “찬성”한다
– 투표로 결정 ~ “리더의 선출”
– 두 번의 투표 ~ 리더 “선출 투표”와 “제안 투표”
두 번의 투표 “정족수가 겹쳐야 한다” “the quorums for those two votes must overlap”
=> 최소 한 노드는 “리더”로 선출한 “내 편”이어야 함 (리더쉽 유지 가능)
ㄴ “내 편” (@) : 리더를 선출한 노드. 리더와 같은 epoch
ㄴ “반대편” (X): 리더를 선출하지 않은 노드. 리더보다 epoch이 작거나 같음
@@@@
—–split-brain———
@XX
제안 투표의 “찬성”이 모두 반대편(리더를 뽑지 않은 쪽)에서 나온다면? “리더쉽” 보장 안됨
ㄴ 반대편 epoch ~ 리더보다 작거나 같음
ㄴ “내 편”의 찬성 없음 => “내 편” 통신 두절 or 새로운 리더
ㄴ “내 편” 쪽에서 새로운 리더가 나올 경우 (나보다 epoch이 큼) => 리더 교체 (과반 충족) 될 수 있음
- 제안 투표의 “찬성”이 모두 내 편(리더로 뽑은 쪽)이라면 ? 통과 (문제없음)
ㄴ 반대편을 신경쓰지 않는 이유는? “리더 선출에서 졌음”
합의의 한계 (Limitation)
“합의” (칭찬부터)
– 분산시스템의 커다란 발전
– 불확실한 야생에 “안전성(Safety)” 속성 부여
ㄴ “동의” ~ No two nodes decide differently
ㄴ “무결성” ~ No node decides twice
ㄴ “유효성” ~ If a node decides value v, then v was proposed by some node.
– “Termination” ~ quorum 기반의 내결함성 (fault tolerant). Every node that does not crash eventually decides some value. (Eventually 결과 보장)
– 전체순서 브로드캐스트 기반으로 내결함성있는 선형성 원자적 연산 구현 (아.. 어렵다 ㅋ)
ㄴ 전체순서 브로드캐스트 : “선형성 쓰기” 보장. 모든 노드에 AOL 전달 및 모든 노드에서 cas 수행. 쓰기성공을 동의로 간주
ㄴ 선형성 원자적 연산 : “선형성 읽기” 보장
ㄴㄴ cas (compare–and–set) => 모든 읽기에 대해 “최신성” 보장 (결과가 흔들리지 않음)
합의의 “한계” (지금부터 본론 …)
– 이득에는 “대가”가 따름 ~ the benefits come at a cost.
– “동기식” 투표 => “성능” 희생 (* 뭐 하나 결정할 때 마다 전국민이 투표하면 … )
– 엄격한 과반수 => 최소 3대 필요 (서버 비싸요 ㅍ.ㅍa;;)
– 고정 멤버쉽 => 투표 노드들이 한 번 결정되면 추가⁄제거 못함 (동적 멤버쉽 어려움)
– 타임아웃 기반 장애감지 => 네트웍 불안정 시 “잦은 리더 선출“로 이어져 “성능”에 영향
ㄴ 네트워크 문제에 취약
멤버쉽과 코디네이션 서비스
주키퍼, etcd
– “분산KV 저장소” or “코디네이션과 configuration 서비스”
– DB와 비슷한데 “합의 알고리즘”이 핵심
– 범용DB 용도는 아님
– 소량의 데이터에 적합 (메모리에 다 올릴 수 있는 사이즈)
– 자주 바뀌지 않는(몇 분 ~ 몇 시간) 데이터에 적합 (런타임 상태저장용이 아님)
주요기능. 주키퍼, etcd 왜 쓰나?
– 주키퍼 사용예) HBase, 하둡 YARN, 오픈스택 Nova, Kafka
– “소량의 데이터”를 일관성있고 내결함성있게 관리할 수 있음 (전체순서 브로드캐스트)
– “분산 락”과 “Lease” 제공 (선형성 원자적 연산)
– 펜싱 토큰 (연산의 전체 순서화) 예) etcd TERM과 revision, 주키퍼 zxid(트랜잭션ID) 와 cversion
– ephemeral node ~ 타임아웃(heartbeat) 노드에 대한 자원(세션, 락) 해제 (장애 감지)
– 클러스터 상태 구독. State–Watch (변경 알림)
노드 작업 할당
– 리더선출 ~ 여러 노드 중에서 리더를 선출. 리더 장애 시 다른 노드 중에서 재선출.
– 리밸런싱 ~ 파티션 분배를 결정. 새 노드 추가 혹은 노드 장애로 인한 파티션 재분배 결정.
– 자동복구 ~ 원자적 연산, 장애감지, 알림(구독) 기능을 잘 이용하여 구현
– 코디네이터 “위탁” ~ 위의 기능들을 직접 구현할 필요없이 주키퍼, etcd 등의 코디네이터 사용
서비스 디스커버리
– 특정 서비스 엔드포인트(IP) 알아내는 용도 (서비스 등록소)
– 읽기 캐시 제공 하기도 함
멤버십 서비스
– “멤버십 서비스 연구” 역사의 일부
– “고신뢰성” 시스템 구축에 중요한 역할 (1980년대 “항공 교통 관제” 등)
– 멤버십 서비스 ~ “살아 있는 멤버”인지 결정
– 장애감지 “합의” ~ 어떤 노드의 “생사”에 대하여 여러 노드들의 “동의”로 결정
– 잘못 선언 될 수도 있음 ~ 실제로는 살아있었지만 (간발의 타임아웃 차이 등)