6.파티셔닝
용어
- 파티션과 유사한 용어가 많음
- DB제품에 따라 표현하는 방식이 많으나 “파티션”을 의미함
- 파티션 ? 대용량 데이터를 여러개로 쪼갠 것. (여러통에 나눠담기)
- DB 제품별 표현
- 몽고DB, ES, 솔라: 샤드 (Shard)
- HBase : 리전 (region)
- BigTable : 태블릿 (tablet)
- 카산드라, 리악: vnode
- 카우치베이스: vbucket
- 책에서는 “파티션”으로 통일
- 파티셔닝 (or 샤딩) : 데이터를 쪼개는 작업 (파티션을 생성하는 작업)
파티셔닝 왜 하나? “대” 용량
- 1대에 저장할 수 없는 문제
- “분산” 해서 대응
- 데이터 너무 많음 (구글 검색데이터 300조) ⇒ 서버 한 대에 못담음 => “데이터 분산”
- 쿼리 너무 많음 ⇒ 서버 한 대로 처리 못함 ⇒ “쿼리 분산”
- 쿼리(질의) or 요청 (둘 다 가능)
- “요청” 보다는 “쿼리”라는 표현이 파티셔닝 주제에 더 적합한 것 같음
- 원하는 “데이터”를 찾는다는 의미를 담고 있고 (Search)
- “쿼리”에 따라 데이터 요청은 다른 파티션으로 향할 수 있음 (방향성)
파티셔닝 골칫거리 (1)
- 쏠림: HotSpot
- 고르게 분산되면 좋겠지만 어느 한군데로 쏠려
- 데이터 쏠림
- 쿼리 쏠림
쏠림 (HotSpot) 없이 잘 분산하려면?
- 적합한 파티셔닝 방법 선택
- Rebalance (재균형화) * 번역체 보다는 그냥 “리밸런스”로 사용
복제(Replication)와 파티셔닝(쪼개기)
- 데이터 분산의 양축
- 복제: 동일한 데이터 복사본 (copy)
- 파티셔닝: 데이터를 여러개로 쪼갬
- 분산 전략에 따라 복제, 파티셔닝 둘 다 사용하거나 둘 중 하나만 사용할 수도 있음
- 대용량 분산 환경에서는 대부분 둘 다 사용 (파티션별 복제전략)
- 다음 두 작업은 “독립적”
- 파티션: 데이터를 쪼개서 저장
- 복제: 여러 노드에 복사본 생성
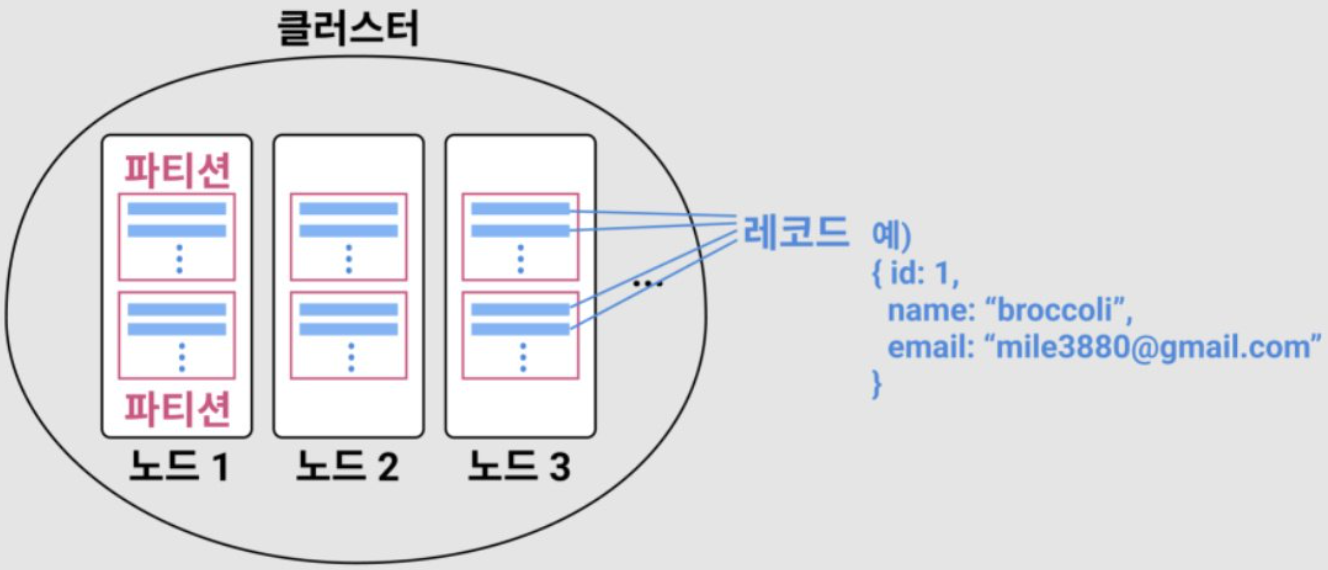
- 파티션 별로 복제해서 서로 다른 노드로 배치(같은 파티션, 같은 노드 ? No No .. 이렇게 되면 해당 노드 장애 시 “Die”)
파티셔닝 골칫거리 (2)
- 위치 결정: 저장위치. 데이터 위치(배치)를 누가 결정하나?
데이터베이스가 결정
- 랜덤 (막 담기) : 별고민없음. 고르게 분산. But, 랜덤이라 풀스캔(다뒤져~) ⇒ 쿼리 시 개고생
- Range (키 정렬) : 데이터에 부여된 키로 “정렬”하고 나누어 담음. 연속적으로 훑기 좋아 (스캔 성능 긋). But, 쏠림 가능성 높음
- Hash (키 사전) : 키를 해싱한 결과로 분산. 랜덤액세스 성능 좋음. But, Range (스캔) 포기
애플리케이션이 결정
- DB 쏠림 해결이 안될 때
- 예) 트위터 인싸 (100만 팔로워) ⇒ DB 혼자서 쏠림 해결 불가앱에서 사용자 아이디 이 외의 다른 조건들을 이용하여 데이터 및 질의 요청을 분산시켜야 함
파티셔닝 골칫거리 (3)
- 위치 찾기: 데이터가 어떤 “위치”에 있는지 어떻게 찾나?
요청 라우팅
- 데이터 위치를 기록한 메타데이터 예) 몽고DB ~ config server
- 인덱스
보조 색인
자동차 검색 예시- 색상으로 검색 : color 보조색인 red : 모닝, K7 white : 그랜저, 소나타, K7 black : 모닝, 소나타, 그랜저- 제조사로 검색 : maker 보조색인 현대 - 소나타, 그랜저 기아 - 모닝, K7
문서 보조 색인
- local index : “파티션”별 생성 하고
- Scatter & Gather : “파티션”별 검색하고 결과 모음
- “쓰기” 빠름 (파티션별로 각자 쓰니 global index에 비해서 쓰기 성능은 좋은듯)
- But, “읽기” 느림 (파티션별로 찾고 모아야 하니.. ㅎ)
용어 보조 색인
- global index : “전체”로 생성
- “읽기” 빠름 (전역적으로 한곳에서 조회)
- But, “쓰기” 느림. 모든 파티션에 대해서 읽고 모아서 써야 함 => 쓰기는 (보통) “비동기” 처리
리밸런싱
- 쏠림 등을 해결하기 위해서 데이터를 재배치
- 데이터가 많을 수록 엄청난 부하를 동반함. 디스크IO 뿐만아니라 cpu, memory, 네트웍,.. 노드 리소스를 엄청 씀
- 이거하다가 몇 번 사고친 경험 (이스터 ㅠ) => low latency를 보장해야 하는 민감한 production 스토리지에서는 절대 안씀
- 그래도 해야 한다면 서비스의 쓰루풋, 부하 상황 등을 고려하여 사람이 개입하는 것이 좋음
- “데이터의 이동을 최소화” 하는 방향으로 진행 => 단순 mod 연산 쪼개기는 불필요한 이동이 많아서 비추
- 리밸런싱을 하는 목적을 기억 => 데이터를 재분배해서 부하를 균형있게 나누기 위함
- 리밸런싱 중에도 서비스는 돌아가야 함 (read/write 가능)
리밸런싱 전략
- mod N (하지마..)
- 파티션 개수 고정 (ex. redis-cluster 16384 slots)
- 파티션 개수를 고정하고 파티션 분할 같은 거 안함. 노드 편입/삭제 시 “파티션 단위”로 이동
- 파티션 개수는 최초에 설정되면 이후로 고정됨 (안바뀜) => 오퍼레이션 심플 (just 이동)
- 파티션 개수를 노드 개수 보다 충분히 많게 생성 => 파티션 개수 == (확장 가능한 최대 노드수)
- 그렇다고 파티션 개수를 무작정 늘리면 또 안됨 => 파티션 관리 오버헤드도 고려해야 함
- 파티션이 너무 크면 리밸런싱 이나 recovery 비용이 크고
- 파티션이 너무 작으면 너무 많은 오버헤드를 야기함
- 새로운 노드 편입 => 노드별로 일부 파티션 단위로 새로운 노드로 이동
- 기존 노드 삭제 => 해당 노드의 파티션들을 n빵하여 나머지 노드로 이동
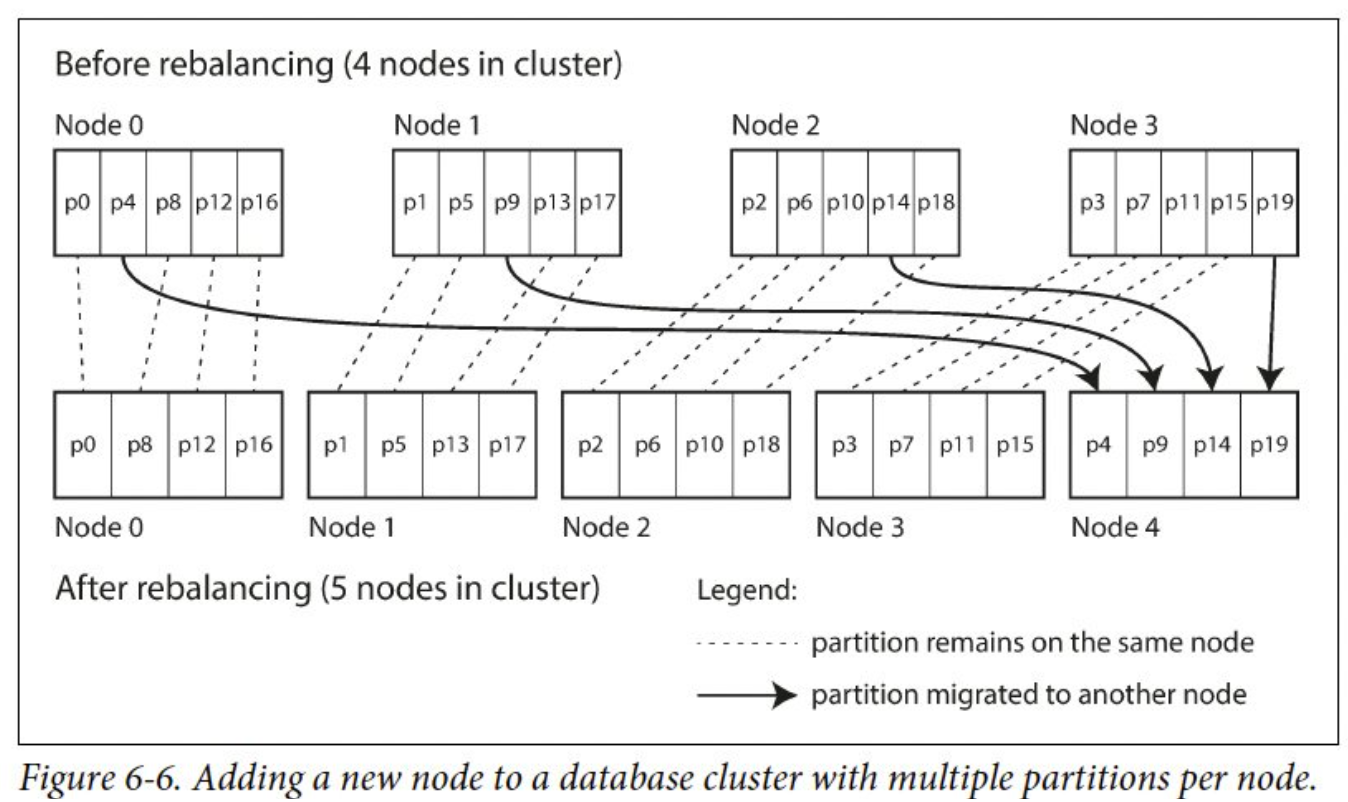
- Fixed-partition DB: Riak, ES, Couchbase, Voldemort
- 다이내믹 파티셔닝
- key range partitioning, a fixed number of partitions with fixed boundaries => 매우 불편
- 왜 불편? 바운더리(경계)를 잘 못 잡으면 특정 파티션만 가득 차고 나머지 파티션은 텅 비어 있게 됨
- “수동으로” 파티션 바운더리(경계)를 재조정? 못할 짓.
- 이런 이유로 range DB (HBase, RethinkDB 등)는 자동(dynamic) 파티셔닝 제공
- 파티셔닝이 설정된 용량 이상으로 커지면 (HBase 10GB) 대략 절반씩 쪼갬 2개 파티션을 만듦
- 역으로 데이터가 대량으로 삭제되어 파티션이 threshold 이하로 작아지면 인접 파티션과 합쳐진다