Series entry
8. 분산시스템의 골칫거리들
분산 환경에서는 예상치 못한 여러가지 문제들이 일어날 수 있습니다. 이 문제들에 대해 알아봅니다.
8. 분산시스템의 골칫거리
대규모 컴퓨팅 시스템의 구축
- 슈퍼컴퓨팅 : 강력한 1대. HPC (Scale-Up, Vertical-Up 접근)
- “결정적” : 예상 가능 (predictable). 분산에 비해 “훨~” 다루기 편함
- But, “SPof” (Single Point of Failure). “소중히” 다루어야. 죽음 끝
- 확장에 한계 (… and … 비쌈)
- 클라우드(분산) 컴퓨팅 : 무수히 많은 N대. (Scale-Out, Horizontal-Scaling)
- 확장성, 가능성 무궁무진 … 그래서 일까.. 이짝~으로 갈 수 밖에 ?
- 무수히 많은 N ⇒ 연결 => 네트워크 ⇒ 야생
분산시스템의 어려움
- “비결정성” : “보장”, “결정” 어려워
- 네트워크 딜레이
- 무수히 연결된 … 장비들 사이의 결함
- 인적 사고/실수 가능성
- 부분장애 (Partial Failures)
- 원자성, 완벽히 되돌리기(abortability) 어려움
- “일부”만 결함 ~ “1 or nothing” 힘들어 (죽느냐 사느냐 그것이 문제로다)
- “장애 인지” 어려움 ~ 동작은 하는 것 같은데 … 이상해 (죽은 것도 아니고 산 것도 아니고)
모든 것이 잘못될 수 있음
- 인정하자 (그게 편함)
- “잘못될 수 있다”를 전제하고 설계 예) Pod is Mortal (Pod는 언제든 듁을수 있다)
- (잘못될 수 있는) 핵심 원인 : “네트워크”와 “시계”
- 역시 … “네트워크” (야생) ~ 분산시스템은 무수히 많은 장비 연결. 다양한 장애와 결함 가능성이 높음
- 시계 ??? (갑자기??)
- 어떤 서버의 시계가 정확한가? (말하기 어렵다)
- 그렇다면 … “시간 약속” 어렵다
모두 다 의심하라
- “신뢰성” (Reliability) 보장 안함 (못함) ⇒ “상어” 해저케이블 사건
- 개발자의 미션 (숙명) ⇒ “신뢰성 없는 요소”를 가지고 “신뢰성 있게 만들기” (도전~~ ㅠㅠ)
- “IP” 사례
- IP는 “신뢰성 없음” ⇒ 패킷 누락/지연/중복/순서바뀜 (인정하자… 문제를 받아들이는 것에서 부터 시작)
- TCP : 신뢰성 있는 전송 구현 ⇒ 패킷 재전송 / 중복제거 / 패킷조립(순서대로)
신뢰성 없는 네트워크
- 네트워크 지연은 필연적인가? No (그건 또 아니라네.. ~.~a;;)
- “선택”에 따른 것임 (어떤 선택?)
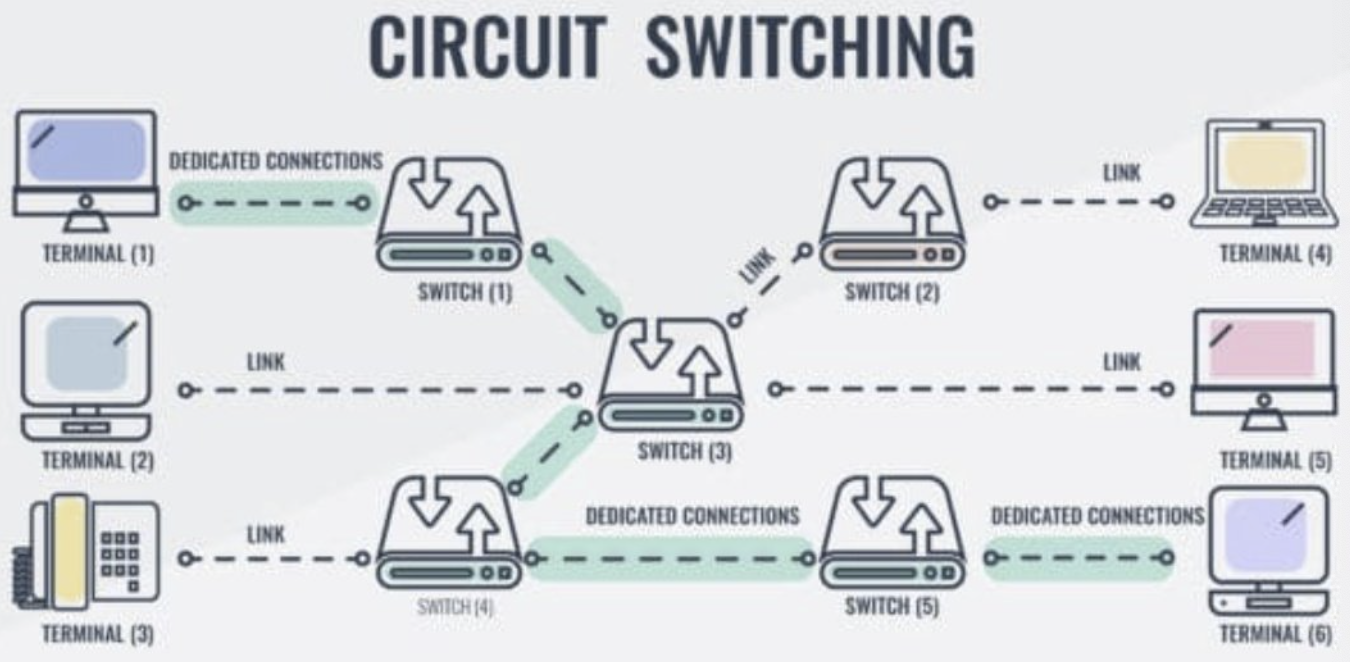
- 네트워크 회선 구축 방식 : 전화망 vs 이더넷 (그림)
- 전화망 (circuit-switched)
- 회선 독점. 쓰고 있는 동안 다른 사람은 못씀
- (독점하니깐) 혼자쓰니 지연발생 가능성 적음. fixed bandwidth, 대역폭 보장(독점)
- (독점하니깐) 회선 연결과정 필요 (Dedicated Path, from-to 전용회선)
- (독점하니깐) 신뢰성 높음. 예측 가능. 간섭없음. (대역폭 내에서 가능한 전송량, 지연시간 등이 예측 가능하고 주변영향 없음)
- (독점하니깐) 회선수 유지 필요 ⇒ 안써도 놀려야 됨(비효율). 비용 부담
- (독점하니깐) 사용자 수에 따라 유동적으로 조절할 수 없음
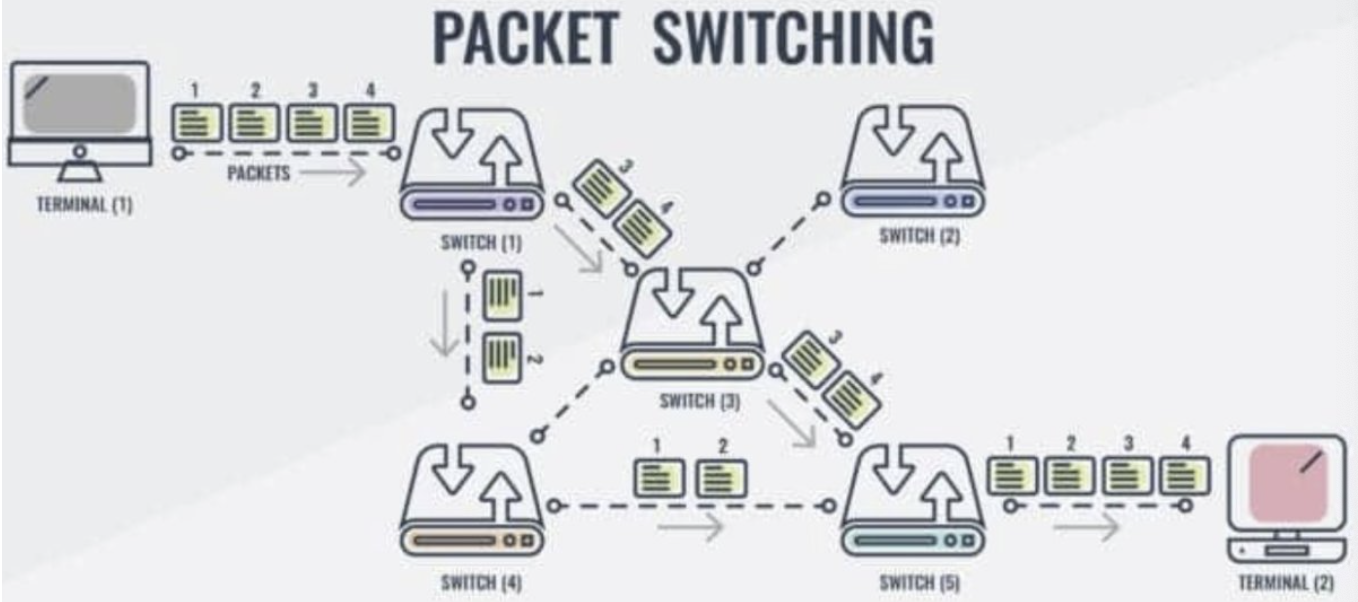
- 이더넷 (packet-switched)
- 회선 공유 (비용절감, 효율)
- (공유하니깐) 회선 연결과정이 필요 없음.
- (공유하니깐) 지연 가능성 발생. (참여자가 늘어날 수록 눈치게임 빡세짐)
- (공유하니깐) Noisy neighbor 이슈 (누가 동영상 다운 받니 …)
- 패킷 사이즈 제한 ~ 보낼 데이터가 크면 쪼개야 됨
- Route path
- 신뢰성 떨어짐 (“신뢰”보다 “돈”을 선택)

- 분산시스템 환경
- 이더넷 기반
- 네! “돈”을 선택 (비용절감, 효율)
- 비동기(async) 패킷 네트워크 ~ 언제 올 지 모르므로 async 하게 다룸 (이제가면 언제오나~)
- 네트워크 결함 감지(Detecting)
- “문제”를 인정하자 (패킷이 지연될 수도 있고, 안올 수도 …)
- 노드 장애 발생 ⇒ 요청을 끊을 수 있어야 함
- 타임아웃 발생 ⇒ Detecting 할 수 있어야 함
- 타임아웃? 얼마나 기다려요?
신뢰성 없는 시계
시계 동기화와 정확도
- 벽 시계, 타이머
- 이벤트 순서화용 타임스탬프 ~ LWW 문제
시계 읽기와 신뢰구간
- 구글 트루타임 API [earliest, latest] ~ 이 구간 어딘가
분산 SSI 문제
- 단일노드 SSI (SnapShot Isolation) => 카운터 “트랜잭션ID”로 충분 (카운터로 선후(인과성) 구분 가능)
- But, 분산환경에서 Globally SSI ? “Global Counter” 만들기어렵다 예) 분산일련번호 생성기
- 동기화된 벽시계 ? “정확도 불확실”
- 신뢰구간 ? 가능은 하나 실험적.
기약 없는 “멈춤”
- 멈춤 문제 => “Lease” 사례 (리더 election)
- 멈춤 예시 ~ VM Suspend, Full GC, Context-switch, 느린 IO Wait, Swap과 Page faults, SIGSTOP/SIGCONT, 노트북 덮개
응답시간 보장하려면
- 데드라인 명시와 준수 => hard real-time
- RTOS, Real Time OS => 명시된 간격의 CPU 시간할당 보장. 동적메모리할당 제한
- Real Time 보장을 위한 막대한 테스트와 측정
- 제약 및 제한 => 언어, 라이브러리, 툴 등
- 많은 비용
- 실시간 => “시간 엄수”
- 고성능 => “처리량”
Full GC 영향 제한하려면
- “stop-the-world”를 인정 ~ 요청을 다른 노드로 라우팅
- “미리 재시작” ~ Full GC 터지기 전에 restart